TIPOS DE BÚSQUEDA DE INFORMACIÓN EN INTERNET

Los Directorios o Índices temáticos (también
conocidos como directorios, catálogos o buscadores por categorías)
Los Motores de búsqueda (o buscadores por
contenido).
Directorios y Motores de búsqueda
son las principales herramientas de búsqueda en la Web. Sin embargo, también
existen otro tipo de herramientas que funcionan como intermediarios en la
recuperación de información, ya que actúan como interfaz único a múltiples
motores de búsqueda. Se trata de los multibuscadores y metabuscadores que no
son buscadores en sí mismos aunque se basen en ellos y su interfaz suele ser
similar a la de los índices temáticos o motores de búsqueda. Estas herramientas
no buscan por sí mismas, sino que limitan a pedir a otros que busquen por ellos.

Podemos distinguir:
multibuscadores
metabuscadores
Los multibuscadores se limitan a
colocar en una página web una lista con los buscadores más comunes y con una ventana de texto para poder enviar la
cadena de búsqueda introducida por el usuario a cada uno de ellos. También
pueden enviar la cadena de búsqueda a una serie de motores de búsqueda e
índices temáticos previamente definidos. Una vez realizada la consulta a los
buscadores prefijados, el multibuscador devolverá la información de todos los
enlaces encontrados. Con la utilización de multibuscadores, el usuario se evita
tener que ir de buscador en buscador hasta encontrar la información deseada. El
usuario elige los buscadores que quiere utilizar y desde allí realiza su consulta
que ofrecerá las respuestas buscador por buscador. La única ventaja es la
posibilidad de consultar un gran número de buscadores partiendo de una única
página. La exhaustividad primará sobre la precisión, ya que el usuario
encontrará un gran número de enlaces y muchas páginas repetidas.
Los metabuscadores también
permiten buscar en varios buscadores al mismo tiempo. Los metabuscadores no
almacenan las descripciones de páginas en sus bases de datos, sino que
contienen los registros de los motores de búsqueda y la información sobre
ellos, adecuando su expresión a los diferentes motores para remitir la consulta
a los motores. Una vez que reciben la respuesta, la remiten al usuario no
directamente, sino tras realizar un filtrado de los resultados. Este filtrado
consiste en eliminar y depurar los enlaces repetidos y en ordenar los enlaces.
Además, sólo aparecerá un número limitado de enlaces, los que se consideren más
importantes. Los más repetidos ocuparán los primeros puestos ya que el
metabuscador considerará que son los más relevantes por estar dados de alta en
mayor número de buscadores. Se trata de herramientas muy útiles, el único
problema es que, por lo general, no permiten realizar búsquedas tan avanzadas
como en un motor de búsqueda, con lo que las consultas tienen que ser generales
y no se puede buscar en profundidad.
Un metabuscador es un verdadero
programa que pueden actuar bien integrado en la propia WWW como el caso de
MetaCrawler o Buscopio, o bien como un programa autónomo, como Copernic, una pequeña
herramienta de software que se instala en el ordenador y permite hacer
búsquedas en varios buscadores a la vez. Existen incluso metabuscadores
especializados en determinadas materias: noticias, bibliotecas, diccionarios,
blogs, software, etc; otros que permiten búsquedas multilingües, e incluso
algunos permiten personalizar las búsquedas con los buscadores elegidos.
Sin duda, uno de los más
conocidos y potentes multibuscadores es MetaCrawler, que permite buscar en
Google, AltaVista, Excite, Infoseek, Yahoo, WebCrawler y Lycos al mismo tiempo,
mostrando todos los resultados de forma conjunta y por orden de importancia.
MetaCrawler también permite la utilización de operadores booleanos y
acotaciones geográficas. Además de buscar en la Web, permite búsquedas en
grupos de noticias y ofrece el servicio MiniCrawler, una pequeña ventana
flotante que permite realizar búsquedas rápidas en MetaCrawler desde cualquier
punto en que nos encontremos.

Directorios o Índices temáticos
Los directorios son listas de
recursos organizados por categorías temáticas que se estructuran
jerárquicamente en un árbol de materias que permite visualizar los recursos
descendiendo desde los temas más generales situados en las ramas superiores, a
los temas más específicos situados en las ramas inferiores. Las categorías
ofrecen una lista de enlaces a las páginas que aparecen referenciadas en el
buscador. Cada enlace también ofrece una breve descripción de su contenido. Así
pues, los directorios o índices se estructuran por temas o categorías
principales que, a su vez, contienen otras subcategorías, y así sucesivamente
hasta que al final se ofrecen enlaces directos a otras páginas o recursos de
Internet.
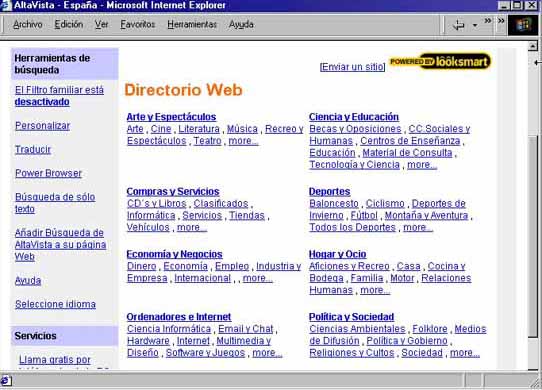
Los Índices o Directorios se
componen de 2 partes:
Una base de datos que contiene las páginas de
los sitios registrados
Una estructura jerárquica que facilita la
consulta a la base de datos
Sin embargo, la formación de un
directorio presenta graves problemas ya que sólo listan una pequeña parte de
los documentos existentes y no suelen estar actualizados. Además, la
clasificación y categorización requieren una intervención manual y en muchos
casos, debido a la heterogeneidad de los temas tratados, algunas páginas
presentan problemas de categorización ya que los índices suelen mantener su
base de datos de forma manual.
La inclusión en un directorio
puede hacerse mediante registro del autor o editor de la página, definiendo las
palabras clave con las que se quiera identificarlo u optimizando el propio
diseño de la página a través de metadatos para que pueda ser indexada de forma
automática.
Motores de búsqueda
La diferencia fundamental entre
un índice y un motor de búsqueda es que mientras los índices mantienen su base
de datos “manualmente”, utilizando para la inclusión de las direcciones a sus
empleados o a los propios internautas que dan de alta sus páginas, los motores
de búsqueda emplean para ello un robot de búsqueda. Estos robots no son otra
cosa que potentes programas que se dedican a recorrer la Web automáticamente recopilando
e indizando todo el texto que encuentran, formando así enormes bases de datos
en las que luego los internautas hacen sus búsquedas mediante la inclusión de
palabras clave. Los robots recorren los distintos servidores de forma
recursiva, a través de los enlaces que proporcionan las páginas que allí se
encuentran, descendiendo como si de un árbol se tratara a través de las
distintas ramas de cada servidor. Luego, periódicamente, visitarán de nuevo las
páginas para comprobar si ha habido incorporaciones o si las páginas siguen
activas, de modo que su base de datos se mantenga siempre actualizada. Además,
estas actualizaciones se realizarán de forma “inteligente”, visitando con más
asiduidad aquellos servidores que cambien más a menudo, como por ejemplo los de
los servicios de noticias.
Y esa es la principal ventaja de
los motores de búsqueda frente a los índices temáticos: la gran cantidad de
información que recogen y la mayor actualización de sus bases de datos. Además,
estos robots permiten a los creadores de las páginas web la inclusión de
“metatags” o etiquetas en lenguaje HTML (entre las cuales pueden incluirse
metadatos normalizados tipo Dublin Core) para resumir los contenidos de sus
páginas y para incluir las palabras claves que las definan. Mediante los
metadatos y las etiquetas, los motores de búsqueda podrán indizar las páginas
web de forma correcta.
Por el contrario, la ventaja de
los Directorios frente a los motores radica en la mayor precisión y un menor
ruido, aunque son menos exhaustivos que los motores de búsqueda, ya que se
obtienen menos resultados.
Los motores de búsqueda no son
otra cosa que enormes bases de datos generadas como resultado de la indexación
automática de documentos que han sido analizados previamente en la Web. Recogen
documentos en formato HTML y otro tipo de recursos. Esta tarea la lleva a cabo
un programa denominado crawler (robot) que rastrea la red explorando todos los
servidores, o limitándose a ciertos servidores siguiendo un criterio temático,
geográfico o idiomático.
La posterior recuperación se
lleva a cabo gracias a la gestión de esta enorme base de datos que permite diferentes
tipos de consulta y ordena los resultados por relevancia, dependiendo de la
estrategia de consulta. Los motores son más exhaustivos en cuanto al volumen de
páginas, pero son menos precisas ya que no interviene la indexación humana.
Existen un gran número de motores
de búsqueda y cada uno presenta diferencias en cuanto al volumen de páginas
indexadas, la interfaz, el lenguaje de consulta, el algoritmo de cálculo de
relevancia, etc. Todas ellas son causa de que, ante una búsqueda, cada motor
presente resultados diferentes.
Para valorar la calidad de un
buscador se deben tener en cuenta una serie de factores:
La exhaustividad: es decir, el número de
documentos que almacena en su base de datos
La periodicidad con que se actualiza su base
de datos (tanto para verificar si hay nuevas páginas, si otras se han
actualizado y si otras han desaparecido)
La calidad, flexibilidad y facilidad del lenguaje
de consulta
La calidad y facilidad que ofrecen tanto la
interfaz de consulta, como la interfaz de resultados
La velocidad de respuesta (el
tiempo que gasta en consultar el índice, aplicar el algoritmo de respuesta y
ofrecer los resultados).
esta bien y es interesante
ResponderBorrarMuy bueno, bueno bueno mmmm :p
ResponderBorrarRikitrix :'D
Te falta packs e.e
Buen trabajo, me ha sido util
ResponderBorrar